
(Word Cloud Designed by Haoning Richter using R Language on June 7, 2018)
Big Data, Hadoop, Audit and Risk Considerations
For the past 10 years, Big Data has been one of the most discussed Phenomena and business challenges in many organizations in the world. However, it has not been discussed much in the internal audit profession. I recently had the opportunity to study big data in depth and thought it may be useful to apply what I’ve learned to the considerations that internal auditors or compliance professionals may face in the big data world: ethics, responsibilities, social and legal obligations, and compliance.
We cannot stop the ever-increasing complexity and volume of data and tools in big data so we shall embrace it by learning and trying to understand what and how we can become more effective auditors to help business and organizations solve problems and achieve business objectives.
Big Data – What is it?
The dictionary says, “extremely large data sets that may be analyzed computationally to reveal patterns, trends, and associations, especially relating to human behavior and interactions.”
Big data includes structured data, semi-structured data, and unstructured data. There are four characteristics of Big Data [1]:
- Volume: The amount of data or data intensity
- Velocity: The speed of data being produced, changed, received, and processed
- Variety: The different data sources coming from internal and external of an entity
- Veracity: The quality and provenance of received data
According to SAS Insights, big data has two additional dimensions [2]:
- In addition to the increasing velocities and varieties of data, data flows can be highly inconsistent with periodic peaks. Is something trending in social media? Daily, seasonal and event-triggered peak data loads can be challenging to manage. Even more so with unstructured data.
- Today’s data comes from multiple sources, which makes it difficult to link, match, cleanse and transform data across systems. However, it’s necessary to connect and correlate relationships, hierarchies and multiple data linkages or your data can quickly spiral out of control.
Big Data – Why Is Big Data Important?
Big data has already affected our lives and work in many ways. Hadoop, one of the top 10 open source tools, has dominated the big data world. Many companies have developed supporting or complimentary solutions to enhance Hadoop so that the Hadoop ecosystem continues to evolve and excel.
The reason big data is so important isn’t about how much you have it but what you do with it. You can collect data (assuming compliance with data privacy and protection regulations) from any sources and analyze it to find answers (or sell to other company), which enable companies to make smarter decisions, market or target the right audience and increase revenue, reduce costs and time, design new product and optimize offerings, recalculating risk portfolios in minutes, and detecting fraudulent behavior or pattern before it affects your organization. As a result, big data can be messy and the traditional data warehousing or data marts can no longer handle the processing nor generate any meaningful analytics.
Ethics in Big Data
In 2012, Kord Davis pointed out the following 4 elements of Big Data Ethics: identity, privacy, ownership, and reputation [3]. Although things have evolved and more “facts” have been surfaced such as the current events in Facebook, those 4 elements can still be relevant in assessing risks, planning an audit, and alignment between documented company values and the practices in methods and tools used (such as algorithms), buying, and selling, etc.
The big data challenges provide the perfect motivation and market demands for new, non-traditional, and effective applications and platforms. Hadoop is one of many open source tools developed to help manage and deal with big data challenges.
Hadoop Background
In 2003, Mr. Doug Cutting worked at a project called Nutch at Google when he had such idea of developing an open source tool for the world to share and to use. In January 2006, Doug joined Yahoo and obtained funding and team resources to develop such open source solution, which they called “Hadoop”.
By 2008, Hadoop scaled. It won the terabyte sort benchmark that year. Hadoop has changed the world by bringing the first scalable, reliable, open-source distributed computing framework to deal with big data across industries. The evolution of Hadoop is driven by its community at Apache, as Doug pointed out. In 2009, Doug realized in order for Hadoop to scale and to be useful in different industries around the world, there needed to be a company providing support for it. Thus, Doug joined Cloudera as the company architect and continues to serve as the Chairman of Apache Software Foundation [4].
The name “Hadoop” was given by one of Doug Cutting’s sons when the son was about 2-year old and called his elephant toy something like “Hadoop”. Doug used the name for his open source project because it was easy to pronounce and to Google. This video provides more details: https://www.youtube.com/watch?v=dImieI08lds
Hadoop Overview
Hadoop is a free, Java-based programming framework that supports the processing of large data sets in a distributed computing environment. It is part of the Apache project sponsored by the Apache Software Foundation [5].
Hortonworks predicted that by end of 2020, 75% of Fortune 2000 companies will be running 1000 node Hadoop clusters in production. The tiny toy elephant in the big data room has become the most popular big data solution across the globe.
Hadoop has the ability to store and analyze data present in different machines at different locations very quickly and in a very cost-effective manner. It uses the concept of MapReduce which enables it to divide the query into small parts and process them in parallel [5].
The following diagram explains different tools in the Hadoop and non-Hadoop Platforms:
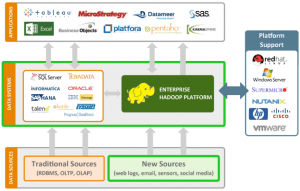
(Image source: jp.hortonworks.com)
Here are 6 Characteristics and Benefits of Hadoop:
- Hadoop Brings Flexibility in Data Processing:
One of the biggest challenges organizations have had in that past was the challenge of handling unstructured data. Hadoop manages data whether structured or unstructured, encoded or formatted, or any other type of data. Hadoop brings the value to the table where unstructured data can be useful in decision making process.
- Hadoop Is Easily Scalable
- Hadoop Is Fault Tolerant
- Hadoop Is Great at High-Volume Batch Data Processing
- Hadoop Ecosystem Is Robust
- Hadoop is Very Cost Effective
Hadoop generates cost benefits by bringing massively parallel computing to commodity servers, resulting in a substantial reduction in the cost per terabyte of storage, which in turn makes it reasonable to model all your data.
Hadoop Architecture with focuses on HDFS and MapReduce
Hadoop is composed of modules that work together to create the Hadoop framework. The primary Hadoop framework modules are:
- Hadoop Distributed File System: Commonly known as HDFS, it is a distributed file system compatible with very high scale bandwidth.
- MapReduce: A programming model for processing big data.
- YARN: It is a platform used for managing and scheduling Hadoop’s resources in Hadoop infrastructure.
- Libraries: To help other modules to work with Hadoop.
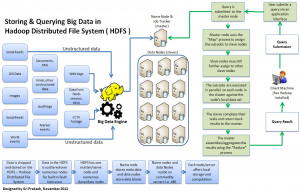
In the architectural level, HDFS needs a NameNode process in order to work on a single node in the cluster and also a DataNode service so as to run on every “slave” node which processes data. The data that is loaded into HDFS is soon replicated and finally split into various blocks which are distributed throughout the DataNodes. The NameNode is accountable for the management and storage of metadata, so that the NameNode notifies MapReduce where the desirable data exists, when any execution framework requests for the data. In case the NameNode or even the server hosting it stops working, HDFS goes down for the whole cluster.
Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in-parallel on large clusters (thousands of nodes) of commodity hardware in a reliable, fault-tolerant manner [5].
A MapReduce job usually splits the input data-set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically, both the input and the output of the job are stored in a file-system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks.
Typically, the compute nodes and the storage nodes are the same, that is, the MapReduce framework and the Hadoop Distributed File System (see HDFS Architecture Guide) are running on the same set of nodes. This configuration allows the framework to effectively schedule tasks on the nodes where data is already present, resulting in very high aggregate bandwidth across the cluster.
The MapReduce framework consists of a single master Job Tracker and one slave Task Tracker per cluster-node. The master is responsible for scheduling the jobs’ component tasks on the slaves, monitoring them and re-executing the failed tasks. The slaves execute the tasks as directed by the master.
Minimally, applications specify the input/output locations and supply map and reduce functions via implementations of appropriate interfaces and/or abstract-classes. These, and other job parameters, comprise the job configuration. The Hadoop job client then submits the job (jar/executable etc.) and configuration to the Job Tracker which then assumes the responsibility of distributing the software/configuration to the slaves, scheduling tasks and monitoring them, providing status and diagnostic information to the job-client.
Hadoop Challenges
Although Hadoop has been widely used in many companies, implementation of Hadoop in production is still accompanied by deployment and management challenges like scalability, flexibility and cost effectiveness.
Spark Cluster
Spark is a cluster-computing framework, which means that it competes more with MapReduce than with the entire Hadoop ecosystem. For example, Spark doesn’t have its own distributed filesystem, but can use HDFS. Spark uses memory and can use disk for processing, whereas MapReduce is strictly disk-based [6].
(Image source: https://www.pinterest.fr)
Although critics of Spark’s in-memory processing admit that Spark is very fast (Up to 100 times faster than Hadoop MapReduce), they might not be so ready to acknowledge that it runs up to ten times faster on disk. Spark can also perform batch processing; however, it really excels at streaming workloads, interactive queries, and machine-based learning. Spark uses memory and can use disk for processing, whereas MapReduce is strictly disk-based. The primary difference between MapReduce and Spark is that MapReduce uses persistent storage and Spark uses Resilient Distributed Datasets (RDDs).
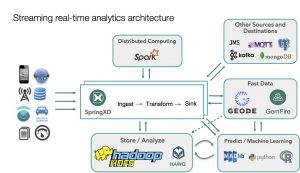
Lambda Architecture
In order to resolve an important issue of latency with the Hadoop system, a new architecture appeared that deals with the large amounts of data at high velocity. In November 2014, Amazon announced the AWS Lambda. It is a serverless compute service that runs your code in response to events and automatically manages the underlying compute resources for you.
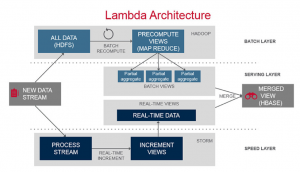
(Image source: https://mapr.com/)
Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch- and stream-processing methods. You can use AWS Lambda to extend other AWS services with custom logic, or create your own back-end services that operate at AWS scale, performance, and security.
Lambda – Pay per use
With AWS Lambda, you pay only for the requests served and the compute time required to run your code besides it offers you a free tier usage. When you go over the free tier, the billing is metered in increments of 100 milliseconds, making it cost-effective and easy to scale automatically from a few requests per day to thousands per second [7]
The Lambda Architecture as seen in the picture has three major components [8]:
- Batch layer that provides the following functionality:
- managing the master dataset, an immutable, append-only set of raw data
- pre-computing arbitrary query functions, called batch views.
- Serving layer—This layer indexes the batch views so that they can be queried in ad hoc with low latency.
- Speed layer—This layer accommodates all requests that are subject to low latency requirements. Using fast and incremental algorithms, the speed layer deals with recent data only.
Hadoop Ecosystems:
The image below provides a good overview of all the tools and applications that were developed to support Hadoop platform in the Hadoop ecosystem.
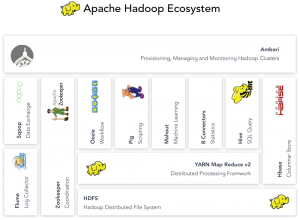
(Image source: www.tamde.us)
Conclusion:
Hadoop and many other open source tools have helped us manage big data, generate meaningful KPIs or dashboards for decision making. The role of an effective auditor shall go beyond just the numbers, charts, or the magnificent characteristics of Big Data.
Perhaps it is time for us to consider and include the following questions in our risk assessment, audit universe, and audit scopes:
What does the company want to achieve? What do those data analytics or numbers really mean? Are the KPI’s measuring the right “things” that really matter to the business and people? Has the company done everything it can to ethically (not just legally) requested, processed, shared, sold, and disclosed necessary information to users, customers, and general public? What are company’s roles and responsibilities in using the open source tools and has company complied its obligations in using and disclosing such open sources?
References:
- “Demystifying Big Data – Tech America Bid Data Report”
- https://www.sas.com/en_us/insights/big-data/what-is-big-data.html
- Kord Davis, “Ethics of Big Data: Balancing Risk and Innovation”, September 28, 2012
- https://www.quora.com/profile/Doug-Cutting
- https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
- https://www.datamation.com/data-center/hadoop-vs.-spark-the-new-age-of-big-data.html
- https://aws.amazon.com/lambda/features/
- https://www.talend.com/blog/2016/05/31/the-lambda-architecture-and-big-data-quality
Recommended Reading:
- Viktor Mayer-Schönberger and Kenneth Cukier, “Big Data: A Revolution That Will Transform How We Live, Work, and Think”, March 4, 2014
- Marc Goodman, “Future Crimes: Inside the Digital Underground and the Battle for Our Connected World”, January 12, 2016


Leave A Comment
You must be logged in to post a comment.